最近ようやく仕事でガッツリFluentdとMongoDBを触るようになってちょっとハマったことが
あったので誰かの役に立つかも知れないので書いておく。
Fluentd界隈は開発が活発なので、数ヶ月後にはこの記事の情報も恐らく古くなっているのでご注意ください。
結論
書いてたら長くなってしまったので先に要点というか結論を書いておく。
apache => fluentd => MongoDB とapacheのアクセスログをMongoDBに入れたときにcodeやsizeといった数値が文字列(string)として入っていたtd-agent.confのformatを自作すると、時間以外のフィールドが文字列(string)として扱われるfluent-plugin-typecast を利用することでcodeやsizeといった特定のフィールドを、stringやintegerなどの任意のデータ型に変換可能。今回の場合はsizeとcodeをintegerとして扱うように変換して解決したMongoDBのAggregation Frameworkは大変便利
前段
MongoDBは2.2からAggregation Framework というのが
使えるようになっていて、これまでMapReduceなどを用いないと実行出来なかったデータの集計作業などが
コマンド一発で出来るようになっているとのこと。
Fluentdを利用してMongoDBに貯めていたapacheのログからvhost毎のトラフィック集計作業を行おうとしてた。
MongoDBに入っているapacheのログデータは下記のような形
1
2
3
4
5
6
7
8
9
10
11
{
"_id" : ObjectId( "515e912431166b166b000002" ) ,
"host" : "hogemoge.glidenote.com" ,
"user" : "192.168.25.84" ,
"method" : "GET" ,
"path" : "/htdocs_error_Zq9kbQHobRDu8hdp4K06lMGUOLwFoY0dQUSsIqgXLVBYB3gwAIBy9NNcd9coPHRV/css/error.css" ,
"code" : "200" ,
"size" : "423" ,
"referer" : "http://hogemoge.glidenote.com/" ,
"agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.31 (KHTML, like Gecko) Chrome/26.0.1410.43 Safari/537.31" , "time" : ISODate( "2013-04-05T08:53:50Z" )
}
hogemoge.glidenote.comの転送量の集計をするために下記コマンドでsizeで集計をかける。
1
2
3
4
5
db.accesslog.aggregate(
{ $match :{ "vhost" : "hogemoge.glidenote.com" } },
{ $project :{ "vhost" : 1 , "size" : 1 } },
{ $group :{ "_id" : "$vhost" , "traffic" :{ "$sum" : "$size" } } }
);
…、集計出来ないッ!
aggregation frameworkで集計出来ない原因
なぜ集計出来ないのか調査すると、sizeが文字列として扱われていた。ちなみに各フィールドのデータ型は下記のような形で調べられる。(ダブルクオートで囲まれているので、その時点でintegerではないんですが調査中は全く気づかなかった…)
1
2
3
4
5
// type 2 で抽出されるものはstring
db.accesslog.find( { size : { $type : 2 } } )
// type 16 で抽出されるものは 32 -bit integer
db.accesslog.find( { size : { $type : 16 } } )
数値が文字列として扱われている問題の原因
同じような現象を調べて下記有益情報を発見。
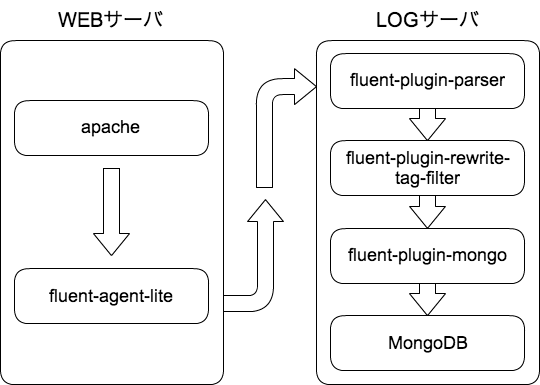
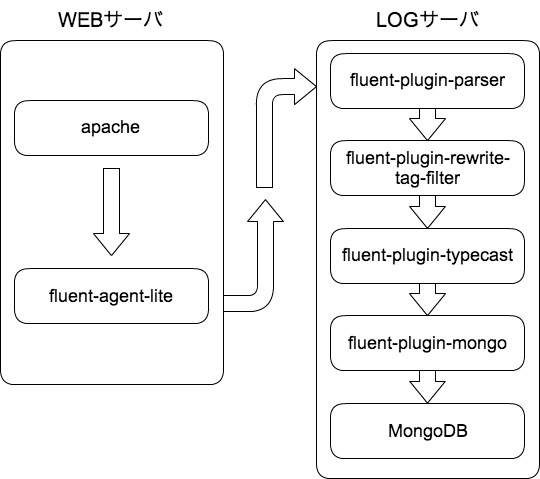
問題が発生した時の構成
問題が発生していたときの構成。(WEBサーバ約200台で、LOGサーバは1台の構成)
結論を言うと今回の現象はLOGサーバ側で利用していたfluent-plugin-parserのfixed_parser.rb 部分で発生していた。fluentdのparser.rb を利用しても同様に発生する問題(2013年4月8日現在)
なぜ数値が文字列(string)として扱われるのか
解決方法を探るためにソースを見てみると、format apache2の場合はApacheParserが利用されてsizeやcodeにto_iの処理が入っており数値に変換されているが、formatを自分で書くとRegexpParserが利用されてtime以外は文字列として扱われている。今回はformat apache2がそのまま利用出来ないログの形式でformatを自分で書いていたのも一因としてある。
https://github.com/tagomoris/fluent-plugin-parser/blob/master/lib/fluent/plugin/fixed_parser.rb#L178-L187
問題の解決方法
問題の原因がわかり、解決方法をいろいろ試していたら、弊社の@banyan 先生からfluent-plugin-typecast というのがあると有益情報をゲット。
早速下記のような形で導入
1
/usr/lib64/fluent/ruby/bin/fluent-gem install fluent-plugin-typecast
td-agent.confのfluent-plugin-typecastの部分は下記のような形
1
2
3
4
5
<match get.apache.access>
type typecast
item_types size:integer,code:integer
tag filtered.apache.access
</match>
apacheのログを流してみると、ちゃんとsizeとcodeが数値(integer)としてMongoDBに入るようになった。
Aggregation Frameworkで再度集計してみる
当初の目的であるMongoDBのAggregation Frameworkを再度試してみる。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
db.accesslog.aggregate(
{ $match :{ "vhost" : "hogemoge.glidenote.com" } },
{ $project :{ "vhost" : 1 , "size" : 1 } },
{ $group :{ "_id" : "$vhost" , "traffic" :{ "$sum" : "$size" } } }
);
{
"result" : [
{
"_id" : "hogemoge.glidenote.com" ,
"traffic" : 289736716
}
],
"ok" : 1
}
一瞬で集計が完了。素晴らしい!!($matchを書けるvhost、timeとかにindex貼ってないと多分死にます)
改善後の構成
この構成で1秒に約4000ドキュメント、1日で約3億5千ドキュメントをMongoDBに突っ込んで
数日様子を見てますが、特に大きな問題も無く稼働中です。
当初どこが問題の原因か全く検討も付かなくて調査に半日近く時間を要した。
仕事でガッツリ触らないと覚えないし、勘も働かないなーと改めて感じた。