TL;DR
- Amazon CloudFrontのアクセスログをBigQueryに入れるようにした
- BigQueryへのデータ投入には社内の他プロジェクトでも利用していて実績があり、KAIZENがメンテナになっているfluent-plugin-bigqueryを利用
背景
ここ2ヶ月くらい、あらゆるログをBigQueryに集約しつつあって、今回はAmazon CloudFrontのアクセスログについて作業をした。
Amazon CloudFrontのアクセスログには以下のような特徴がある。
- Amazon CloudFrontのアクセスログは数時間〜1日程度遅れでS3のBucketに追加される。時系列はバラバラ
- CloudFrontのアクセスログがtsv形式。
- ベストエフォート型で全てのログがS3に収容される保証は無い
gzで圧縮されてS3に追加される(BigQueryに入れるにはgz形式から展開する必要がある)- ログファイルの数が非常に多い。作業していた環境でだいたい1日に15,000個くらい
gzファイルがあって、全部をダウンロードするのに160分くらいかかる
という感じ。
仕組みの詳細
データの流れ
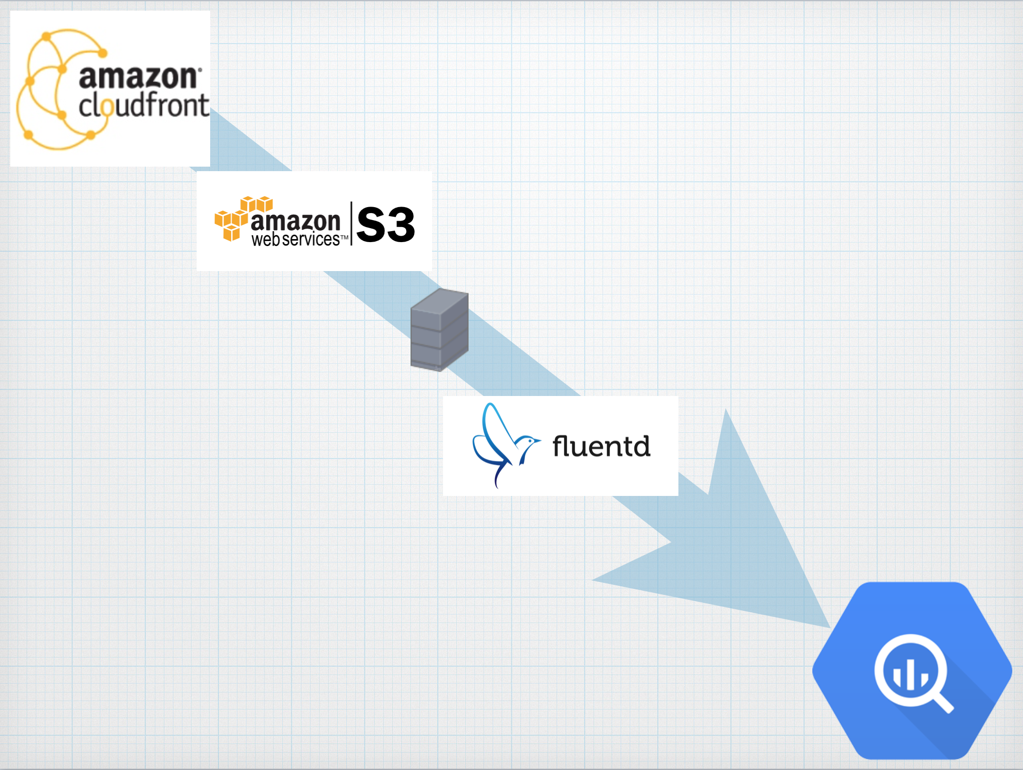
- CloudFrontのログが自動でS3に追加される
- batchサーバから
s3cmd syncでcronで定期的にs3からログファイル(gz形式)をローカルに持ってくる - batchサーバで、取得したログファイルを
zcat ${FILE} >> /var/log/cloudfront/access.logで連結する - batchサーバのFluentdで
in_tailを用い/var/log/cloudfront/access.logを読み込む fluent-plugin-bigqueryを用いてBigQueryにデータを投入する(日付毎にデータ投入先のテーブルを分ける)
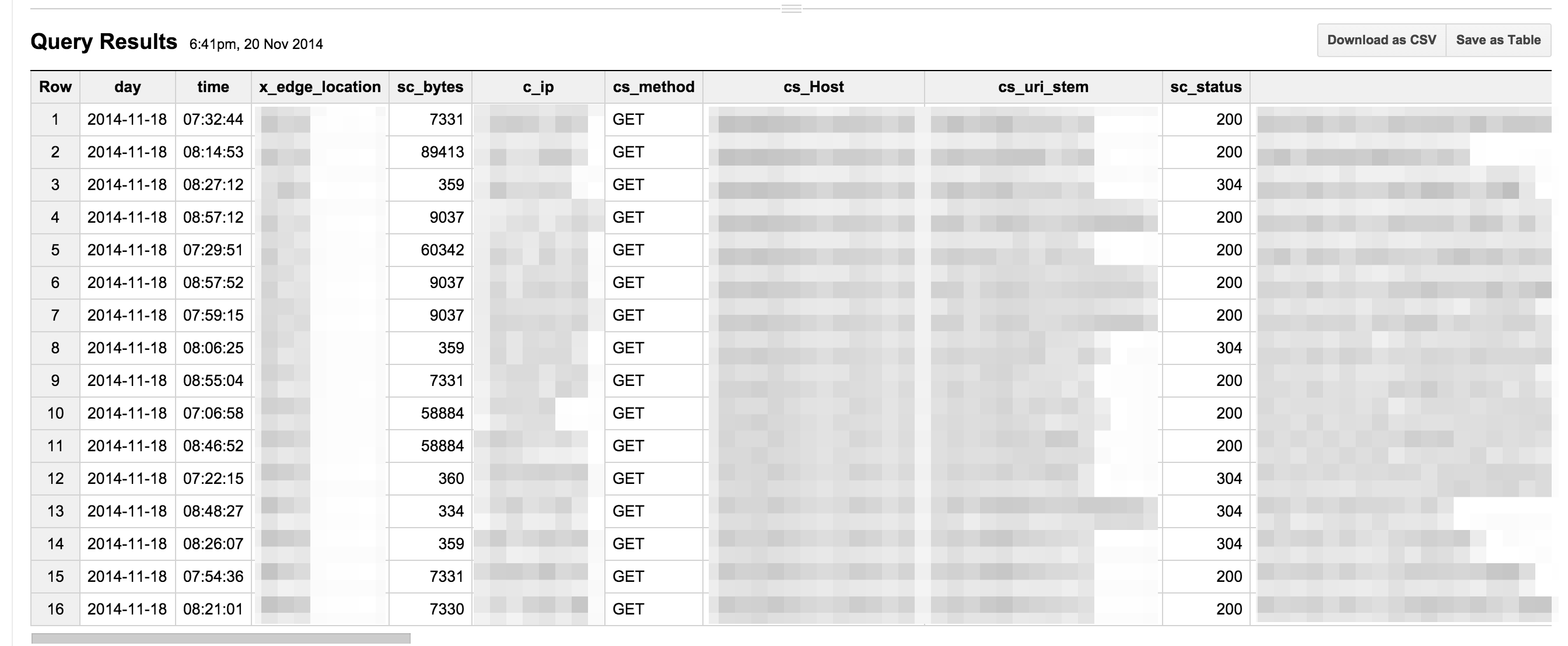
こんな感じでBigQueryにデータが入っている
先日発表されたS3 Event Notificasionsを検証中なので、問題が無ければ、Amazon SQSを利用した処理に切り替え予定。
この方式を採用した理由
- 私がFluentdの運用に慣れていた。
- KAIZENがメンテナをしているfluent-plugin-bigqueryを利用したかった
- BigQueryへのデータ投入部分を自前で実装しなくて良い
- BigQueryへのデータ投入周りのエラーハンドリング、再送処理をfluent-plugin-bigqueryに任すことが出来る
- logrotateを利用して、ログの世代管理が出来る。Fluentdがログ切り替えを検知出来る。(nginxのログなど他のアクセスログと同じような感じで扱える)
- Fluentdを利用しているので、スケールが容易
/var/log/cloudfront/access.log-YYYYMMDD.gzというように日別でログが分かれているので、障害やトラブル発生時のリカバリーも簡単になっている。(障害が発生した日の15,000個とかのログをS3から持ってきて云々… みたいな面倒な処理が必要ない)
その他
- CloudFrontのログがS3に追加されるのが遅い場合1日程度かかるので、翌日のテーブルにデータが入ってしまう。BigQueryからデータを取り出すときに工夫が必要
- BigQueryにデータ投入先のテーブルが存在しないと死ぬので、別でテーブル作成の仕組みと監視をしておく必要あり。
- データサイズが大きい場合、テーブルを適切に分割していないとBigQuery破産に。
- テーブルの自動作成、監視にはbigqueryを利用
該当部分のtd-agent.confの設定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | |
BigQueryにログを集約したことで集計も調査も非常に簡単になって、本当にBigQuery素晴らしい。