![]()
新規サービス用の監視をNagiosからsensuに切り替えて2ヶ月経ったので、 導入時の調査で社内で公開してたissueと、投入して2ヶ月間運用した記録を公開しておこうと思う。
というか以前Sensuの事を書くと公言していたのに、すっかりサボっていて 昨日@ma0eさんのブログを見て下記のやり取りを思い出して急いで書いた…
@ma0e We started using it. @glidenote will report the detail soon, I think.
— kentaro (@kentaro) 2013, 10月 30@kentaro @glidenote that would be nice
— Mitsutoshi Aoe/maoe (@ma0e) 2013, 10月 30導入環境はCentOS 6.4で、利用しているsensuのバージョンは0.12.1-1になり、基本的にはNagiosとの比較になります。
またPuppetを使っているので、導入にはsensu-puppetを使ってます。
箇条書きで読みにくいですが、sensu導入の際は参考にしてください。
Sensuの特徴
- Nagiosの問題点から生まれた監視フレームワーク
- Rubyで書かれている
- 監視対象(クライアント)が自動登録される
- 設定ファイルが簡潔、分かりやすい
- 新規サーバにChef/Puppetを流した直後から監視が自動で開始される
- 既存Nagios Checkの再利用が出来る(Nagios資産が活かせる)
- EC2のようなサーバ構成が頻繁に変化する環境において非常に有用
- Chef/Puppetとの相性が非常に良い
- 必要な機能はプラグインで拡張。アラートの通知方法を追加したり、librato-metricsと連携して、メトリクス作成とかも出来る。
- WEB UIの動作が軽快
- スケールアウトが容易
より詳しい情報は公式スライド http://slides.sensuapp.org を参照
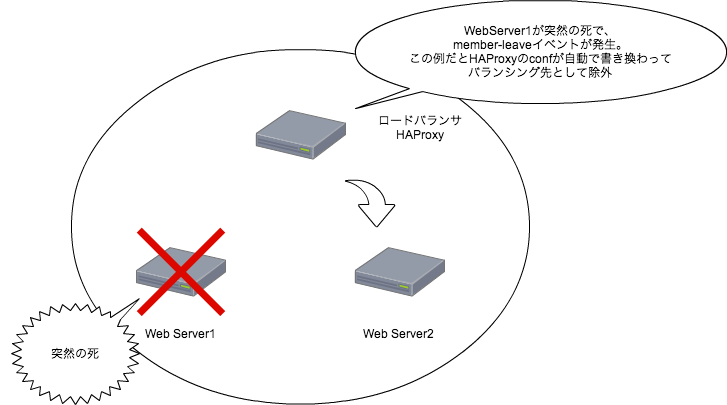
sensuと連携出来るサービスとしてスライドには下記の画像が載っている

導入前の検証、調査時のまとめ
- sensu repoを追加すれば、yum一発で導入出来る
- sensuにはサーバとクライアントがある
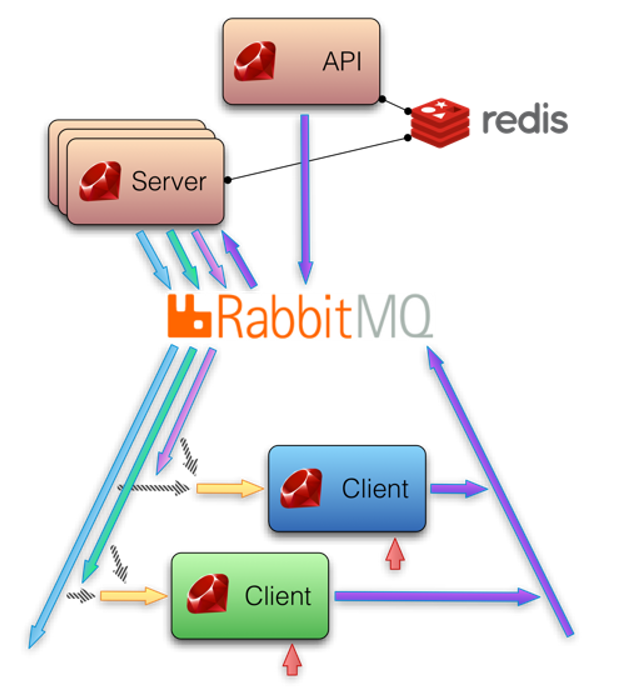
erlang、RabbitMQ、redisとgemのsensu-pluginが必要。クライアント側はredis必要無い- sensuは
sensu-server、sensu-api、sensu-dashboard、sensu-clientの4つから構成されている - Nagiosのようにサーバからクライアントに状態を聞きに行くのではなく、クライアント自身が自分を監視している
- クライアント側で監視がこけたらサーバ側に
RabbitMQを使って、サーバ側に自身の異常を通知する - クライアントに設定ファイル、監視プラグインを渡して
sunsu-client起動すれば監視が勝手に始まる。(極端な話/etc/sensuまるごとクライアントに渡せば良い) - サーバはクライアントを
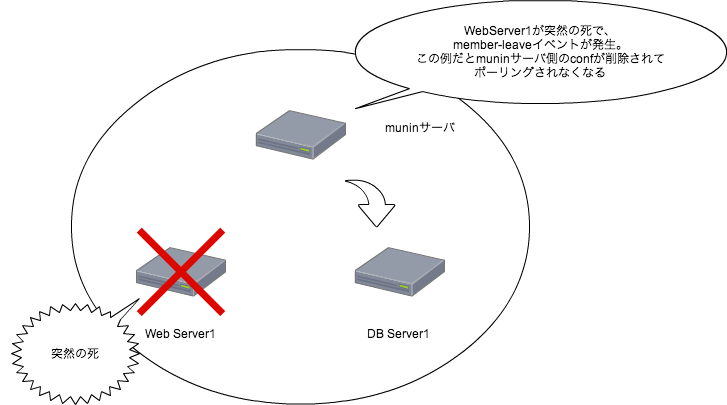
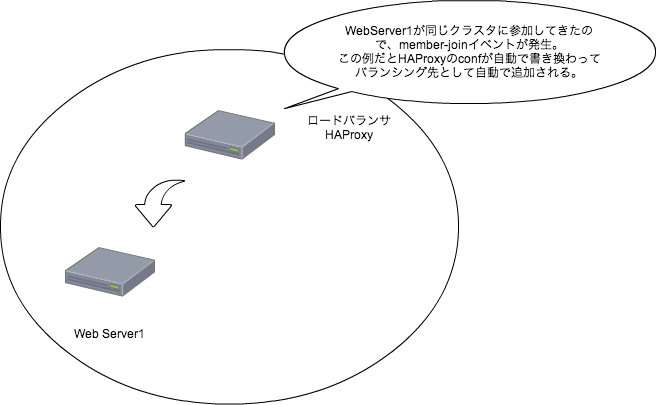
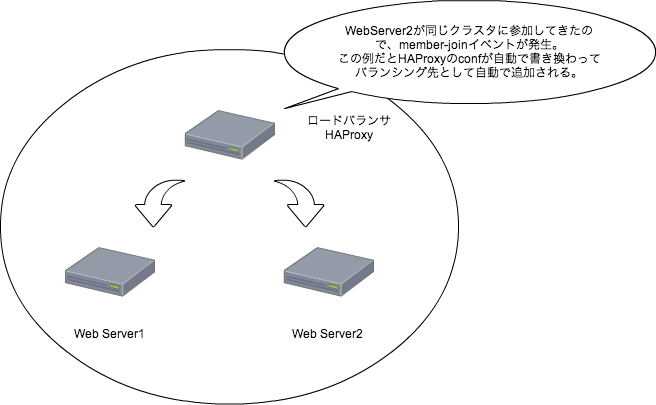
RabbitMQで定期的に通信していて、通信断やホストダウンはサーバ側が検知する - クライアントが増えた場合は、
RabbitMQ経由でサーバに通知してきて勝手に監視対象に追加される - クライアントを削除する場合は、api経由で監視対象から外す。(管理画面があるのでそれで監視対象を管理出来る)
- 設定ファイルはjson。手編集ではなく、chefやpuppetでの自動生成が推奨されている
- sensu自体が、chef/puppetでの管理が推奨されている
- Nagiosと比較して設定ファイルが分かりやすい(Chef/Puppetが生成してくれるので自分で書くことはないと思いますが)
- apiがあるので、自前でツールを用意したりするのが楽そう。(後述する
sensu-adminもapiを叩いているツール) - nrpe-pluginがそのまま使えるのでnagios時代の資産が使える。
/usr/lib/nagios/plugins/check_load -w 20,500,500 -c 35,500,500とかをチェックコマンドとして設定すれば良い。 - 監視プラグインの書き方はnagiosと一緒。sensu-pluginも公開されてる https://github.com/sensu/sensu-plugin
- 通知プラグイン、アラートのトレンドをグラフ化してくれるプラグインなどもある。
導入、2ヶ月運用したまとめ
- sensu-puppetを動かすまでかなり苦労した(どうやらChefだと導入が簡単らしい)
- 日本語の情報がほとんどない。特に
sensu-puppetは、英語のドキュメント自体ないのでmanifest読まないといけなくてかなりつらい sensu-puppetが動くようになると、設定ファイルを作ってくれるので一気に全台に導入出来るようになる。監視項目追加なども非常に楽になる- 逆に言うとsensu-puppet(sensu-chef)を利用しない場合は、sensu採用する意味が薄い(と思う)
RabbitMQの管理にはpuppetlabs-rabbitmqを利用した- デフォルト管理画面の
sensu-dashboardが簡素すぎる(設定項目が少ないので分かりやすいとも言えますが) - 標準管理画面(
sensu-dashboard)に機能追加したsensu-adminというのがあり、これを導入するとダウンタイムなどを設定出来るようになる。 sensu-adminはRailsアプリなので、nginx+unicorn+upstartで上げてます。- sensuのプラグインだと足りないので、nrpe-pluginを結構使ってる。
- ログもjsonで吐かれるので、jqを一緒に導入しておくのが良い
sensu-serverを再起動したタイミングで、sensu-apiが死ぬことがある。なのでsensu-apiの監視必須sensu-serverを再起動する必要がある場合は、sensu-server,sensu-api両方再起動しておくのが吉- IRCの通知プラグインが簡素過ぎたので、色が付くようにPR出してmergeしてもらった colorize irc notification. by glidenote · Pull Request #329 · sensu/sensu-community-plugins
- 各種プラグインがRubyで書かれていて、それぞれのファイルが短いので理解しやすい。改変や自作も楽に出来る。(Ruby情弱の私でも出来た)
- 今Sensuで監視しているサーバは10台弱で、各サーバ8〜10個くらいの監視項目という小規模で利用していて、2ヶ月間トラブルもなく安定している
- 数百台と監視したときNagiosと同等の安定した動作がするかは調査中。
- 私がRabbitMQの扱いになれてないので、そこがトラブると調査が大変そうな予感…
実際に稼働しているsensu-serverの/etc/sensu配下のファイル一覧。.jsonが設定ファイルで、.rbがプラグイン。sensu-puppetが設定ファイルを生成してくれるので、管理が非常に楽。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | |
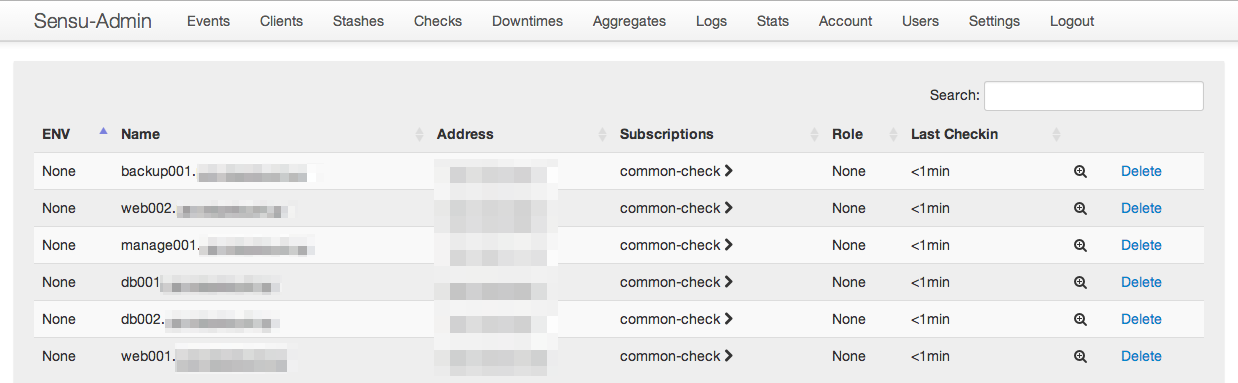
実際に使っている管理画面。sensu-dashboardからsensu-adminに切り替えてサービスに投入してます。
アラートが出ると下記のような感じ。アラートが出たものだけ表示される。
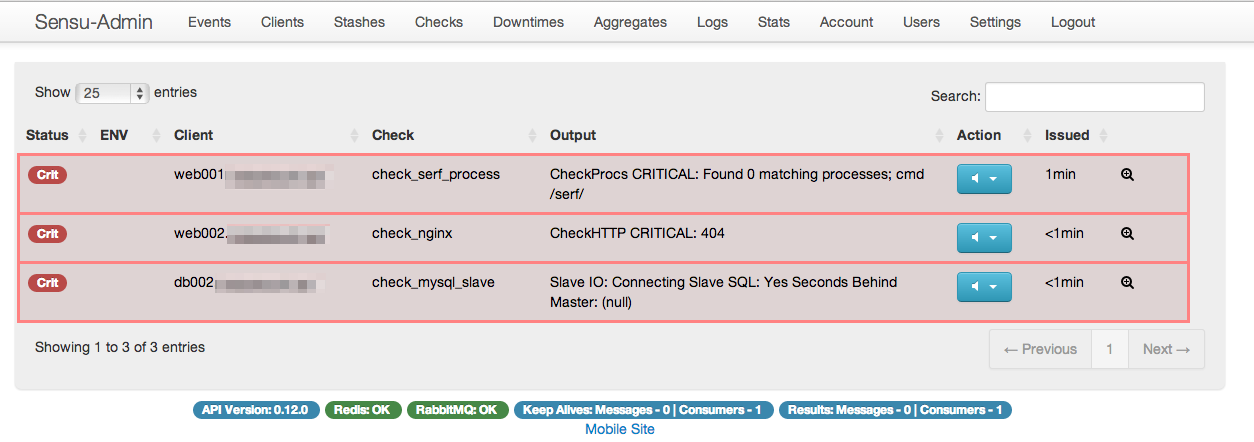
IRCには下記のような感じ(私のPRがmergeされて色が付くようになってます!)

メールでは
1 2 3 4 5 6 7 8 9 10 11 | |
みたいな感じで通知される。
私が導入したときはVersion 0.9だったのが今はVersion 0.12になっており、ドキュメントの更新も結構活発なので、 導入に関しては公式ドキュメントを読むのが良いと思います。
Puppetでの構築
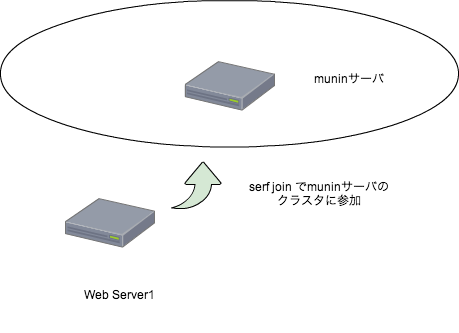
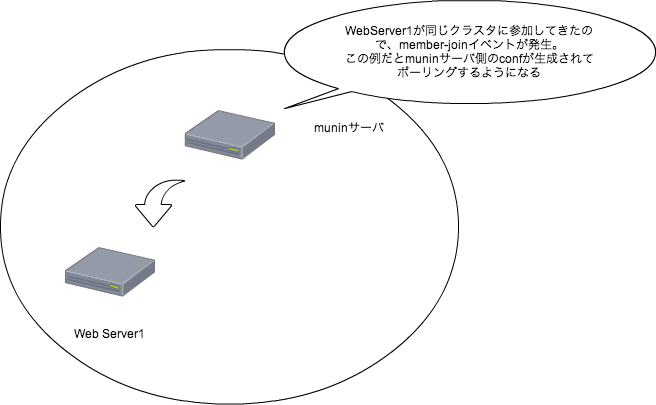
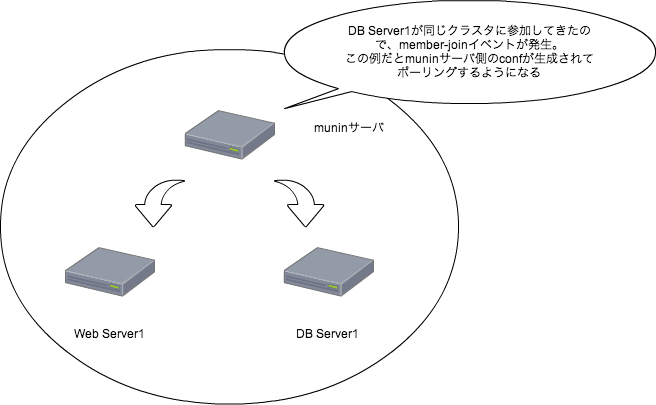
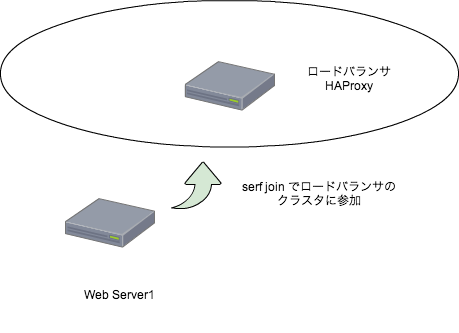
実際に構築時に流しているコマンド、下記を流せば、Sensuでの監視が勝手に始まる。 Serf-muninも使っているので、下記を流し終われば即サービスに投入も出来る。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | |
SensuとともにSerf-muninを導入したこともあって、インスタンス起動して、 Puppet流したら即サービス投入可能という、手間のかからない環境が出来上がった。
数百台、数千台の監視になるとどうなるか分からないけど、今の規模では非常に安定しているし、 Sensuの管理の簡単さを知るともうNagiosには戻りたくない。