結構前に作っていたんですが、いろいろと忙しくてブログに書くタイミングを失していたので年末のタイミングで紹介。
TL;DR
- GoReplayを利用して、Production環境のリクエストを複製し、Stagins環境、開発環境に投げる仕組みを作った
- インフラ構成の大きな変更無しで、手軽にProduction環境の実リクエストを複製し、開発、動作検証ができるようになった
- 2016年の弊社サービスのDocker化や、インフラ構成の大幅な変更、ミドルウェアのアップデート、アプリの改修時のバグ事前検知と事故防止に大いに役に立った
GoReplayの説明
- Goで書かれており、バイナリを設置し、オプションを指定し実行するだけで動作する
- アプリが稼働しているサーバで動く。(例えばNginx+Railsが稼働しているサーバで一緒にGoReplayを動かす感じ。)
- libpcap を利用しているので、tpcdumpと同じでデータリンク層(OSI layer2)レベルでパケットを取得しています。
- GoReplay は
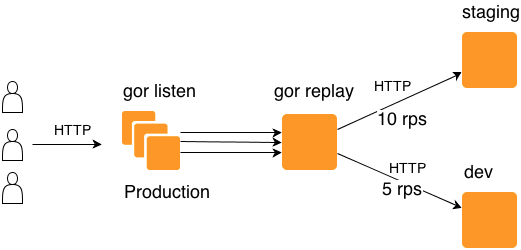
gor listenとgor replayの2つが1セットで動作します。gor listenがリクエストを複製し、Appとgor replayに渡す。gor replayがリクエストを転送したり、ファイルに書き込んだり、再生作業をする。
- 複製の割合や、複数の転送先、リクエストのフィルタリング設定などがあり高機能。
私の理解が正しければ下記のような感じで動作してます。
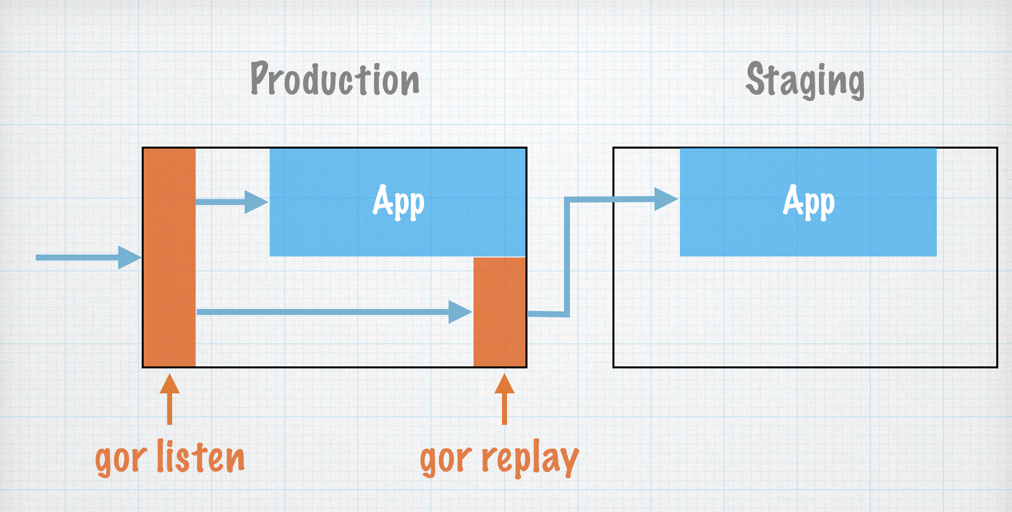
Shadow Proxyとの比較
- アプリサーバで必要な時に手軽に動かせる。
- 動作が軽快
- インフラ構成的に利用時に事故が起こりにくい(サービスの全リクエストを裁くわけではないので)
今回なぜShadow Proxyを利用しなかったのかは後述。
実際に稼働している例で説明
実際に弊社で動かしている環境をざっくり図にして説明。
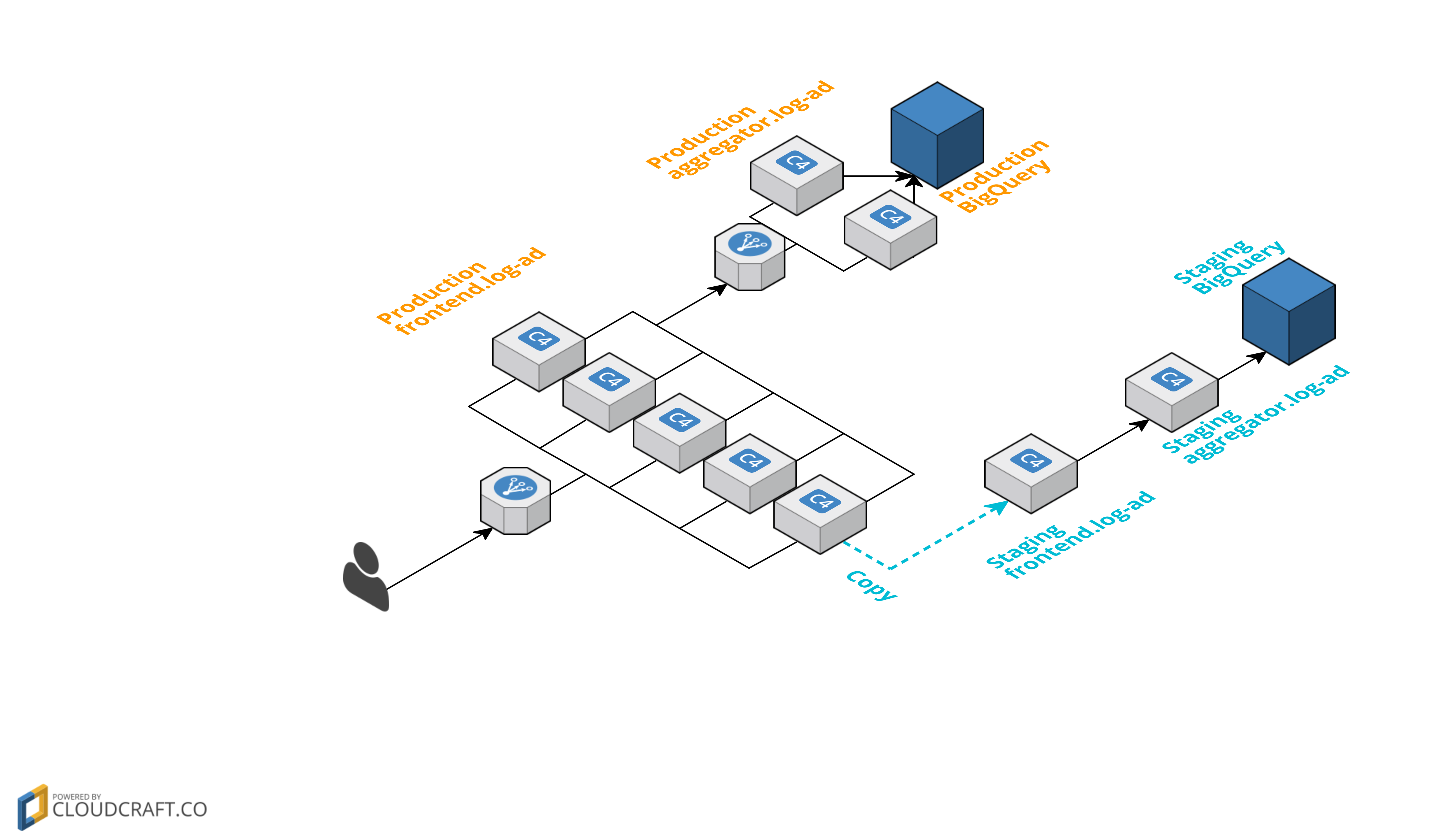
- Productionリリース予定のコードがデプロイされている、Stagingサーバを用意。
Production frontendの1台で、GoReplayを動かしリクエストを複製し、ステージングサーバStaging frontendにリクエストをProductionと同じリクエストを投げる。- Productionのデータと一緒にならないように、ステージング用に
staging aggregatorと データ格納先のstaging BigQueryを用意。 - 下記コマンドのような形で動かし、Productionの1台に流れてきたリクエストを10%の割合で複製し、ステージングサーバに転送します。
- echoサーバを作って、ベンチをとった結果(後述)、リクエストを100%複製し転送すると、パフォーマンスが劣化するので複製・転送の割合10%だけにしてます。
- 実際の運用ではSupervisordを利用して、GoReplayの軌道を管理
- 次期リリース予定のコードやインフラに問題があれば、StagingサーバのbugsnagなどがキャッチしてSlackにPostされる。
1
| |
GoReplay利用時のベンチマーク
nginx + echo-nginx-module を利用して、GoReplayの複製割合に応じてどれくらいパフォーマンスが劣化するか下記のような形でベンチマークを取得。
1
| |
0%はGoReplayの利用無し、100%の場合はGoReplayで全トラフィックを複製して転送する。
| 0% | 10% | 20% | 50% | 100% | |
|---|---|---|---|---|---|
| RPS | 2254.49 | 1944.42 | 1782.10 | 1403.82 | 1023.71 |
GoReplayで転送率を100%にして、全トラフィックを複製かけるとパフォーマンスが劣化するので、インフラを増強しておく必要あり。
ここから余談で、どうしてShadow Proxyを導入しなかったのか過去の経験と個人的な意見をちょっと書いてみる。
リクエストを複製するShadow Proxyの話
リクエストを複製するShadow Proxyと呼ばれるものは昔から存在します。
- cookpad/kage: Kage (kah-geh) is a shadow proxy server to duplex HTTP requests
- lestrrat/p5-Geest: Port of Kage
- kentaro/delta: HTTP shadow proxy server written in Go
Shadow Proxy利用時の一般的な構成

Shadow Proxyの問題点(※1)
- 構成的にロードバランサの次あたりに存在(リクエスト処理する構成の前段の方に存在)するので非常に高い信頼性が求められる。
- 構成的に全リクエストがShadow Proxyを経由し、backendのサーバに到達するため、Shadow Proxyがボトルネックになりやすい。
- 各種Shadow Proxyのベンチマーク Go言語を含む複数種類の言語により実装されたソフトウェアのベンチマーク - Qiita
- インフラの構成的にサービスの全リクエストを処理する必要があるので、気軽に利用出来ない。稼働中のサービスに後から投入しにくい
- 全リクエストがShadow Proxyを通過する構成になっていると、Shadow Proxyが落ちるとサービス全部落ちる
- 上記を解消しShadow Proxyを安定的に稼働しようとすると、インフラが複雑化して障害点が増えやすい
※1 2年以上前の経験から得た知見なので、もしかして今は違うかもしれませんが。
この仕組みを作ったおかげで、Production環境のリクエストを利用し事前に動作検証が出来るので、今年は事故も心理的な負担がだいぶ減ったと思う。