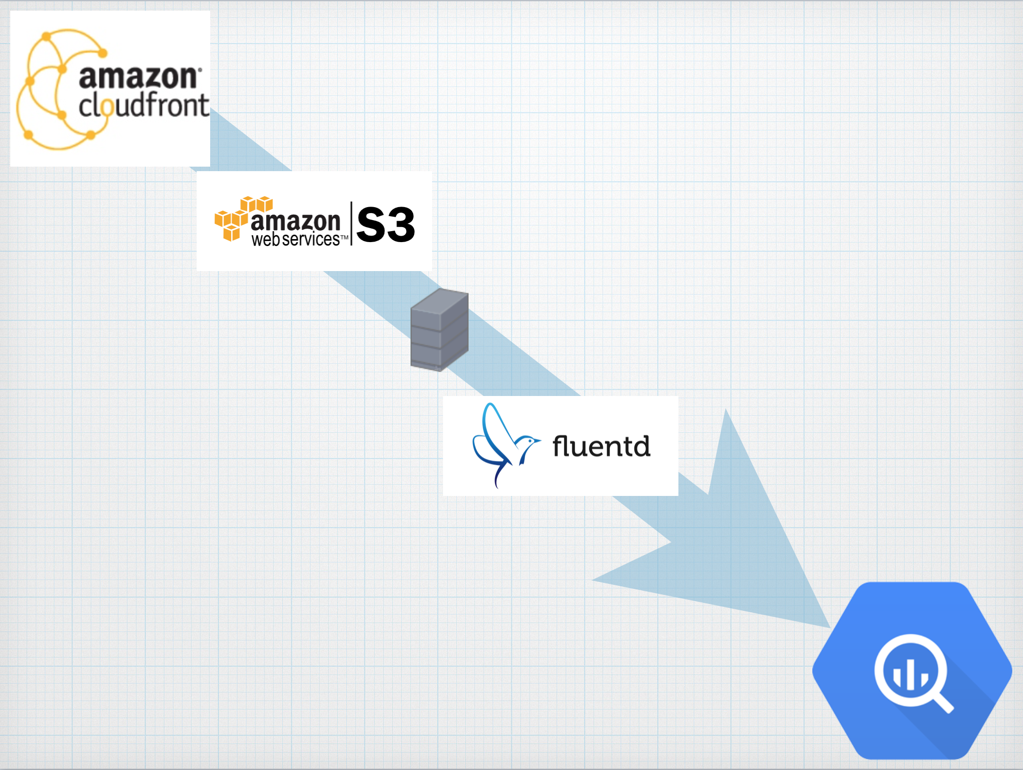
Serverspecを執筆されたmizzyさんからご恵贈頂きました。ありがとうございます。
本書の詳細な紹介はあんちぽさんのブログと、mizzyさんが出演したRebuildがオススメです。
- Serverspecの作者がつくる、あるひとつのOSS文化 - 書評『Serverspec』 - delirious thoughts
- Rebuild: 75: Book Driven Development (gosukenator)
事前に断っておくと私がここで記載している「インフラエンジニア」はITインフラエンジニアの話です。
以前サーバ/インフラ徹底攻略を本ブログで紹介したあとに、 書内のある特集を執筆担当された方と話していて、
Web系インフラエンジニアがどんどん先鋭化されつつあって、この本の内容を理解出来る人ってどれくらいいるんだろうね
という事を仰っていたのが非常に印象的であった。
先鋭化という言葉を聞いて、昨今のWebインフラエンジニア界隈の技術を思い起こすと、 Serverspecの登場以前、以後でその先鋭化具合が顕著になったと個人的に思っている。
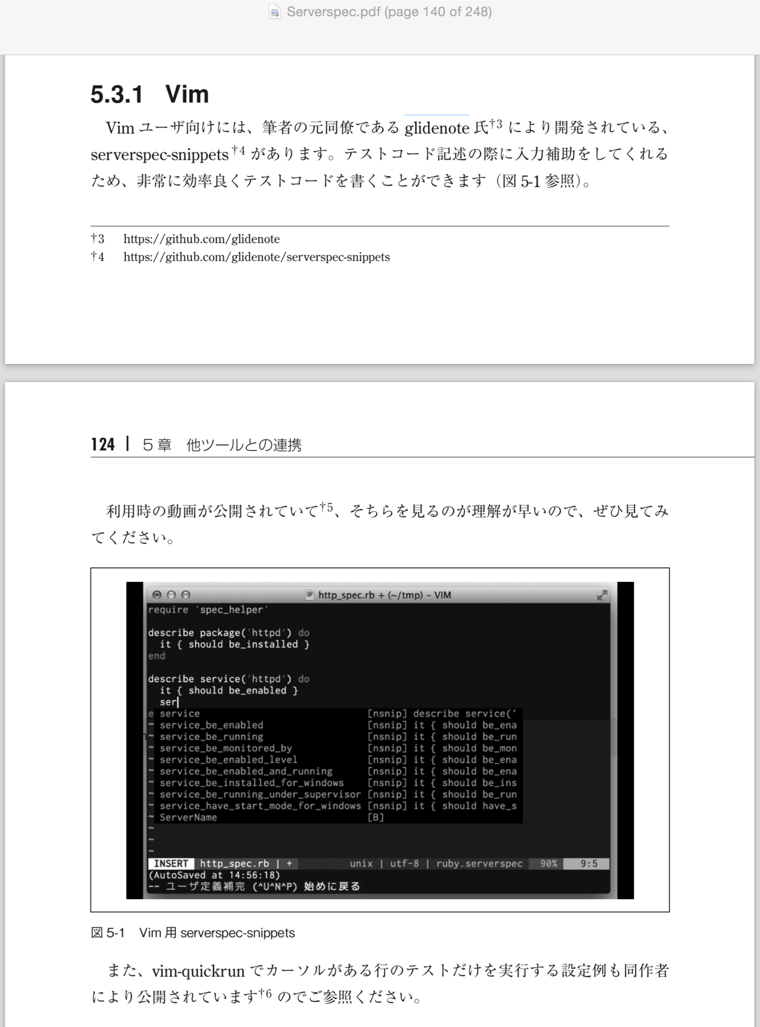
サーバのテスト標準ツールとなったServerspec
ServerspecはWeb系インフラエンジニアに待望されていたものであり、 その登場により現在のサーバ構築において
- PuppetやChefなどでインフラのコードを書く
- 適用する
- Serverspecでテストを実行する
という一連の作業がスタンダードになった。
サーバ構築の一連の作業において一番面倒な確認作業をコードに出来ることで、 自動化、属人性の排除、CIはもちろん、何が設定されていて、何が動いているのかなどインフラの透明性を高める事が可能になった。
またserverspec/serverspecのcontributorsを見ると、 Web系インフラエンジニアが非常に多いことから分かるように、作者のmizzyさんを中心に、 Web系インフラエンジニアが自分たちで使うためにPRを送り、それが取り込まれ機能拡張され進化したツールだと思っている。
Kaizen Platform, Inc.でのServerspec利用
私の現在勤めるKaizen Platform, Inc.においても、技術顧問であり本書の前書きを担当した伊藤直也さんによって
Serverspecは導入され、インフラエンジニアのyoshiakisudo、@m_doiによりChef + Serverspec + GitHub + CircleCI + Docker を組み合わせる形に進化し、
- Chefのレシピを書く。Serverspecのテストを書く
- GitHubにPushする
- GitHubへのPushを契機にCircleCI上に新規にDockerコンテナを立て、Chefを適用
- DockerコンテナにServerspecを流してテストを実行する
というサイクルを1日に十数回まわして、インフラの継続的な改善を行っている。
サーバへのChef適用
余談であるが、サーバへのChef適用は@m_doiのより昨年夏からChatOps化されており、
チャット(Slack)上からhubot経由でGitHub上にデプロイ用PRを作成
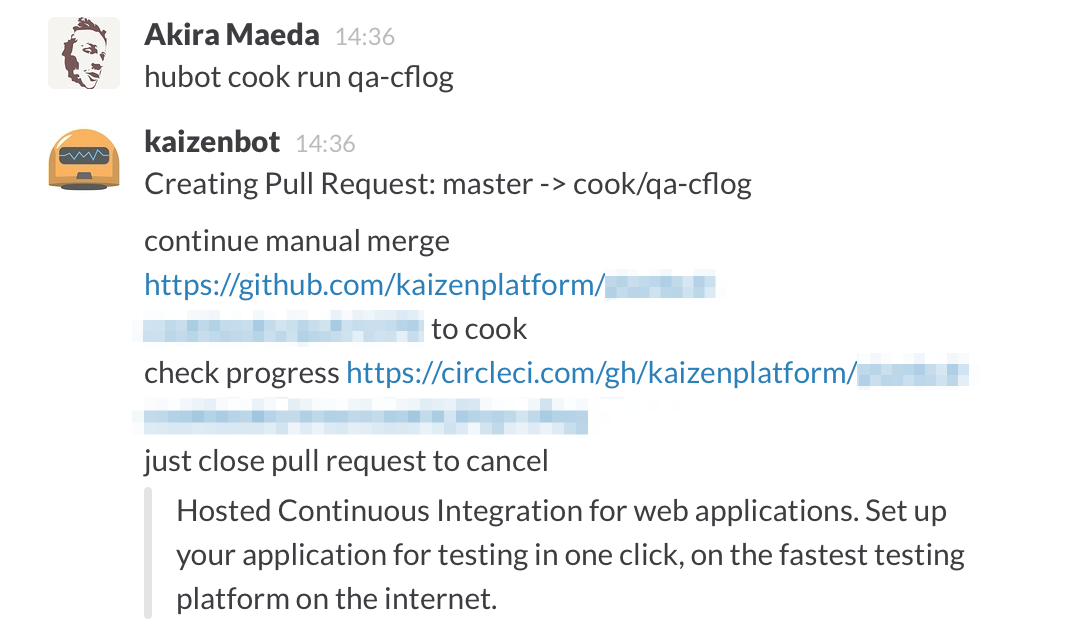
作成されたPRのmerge
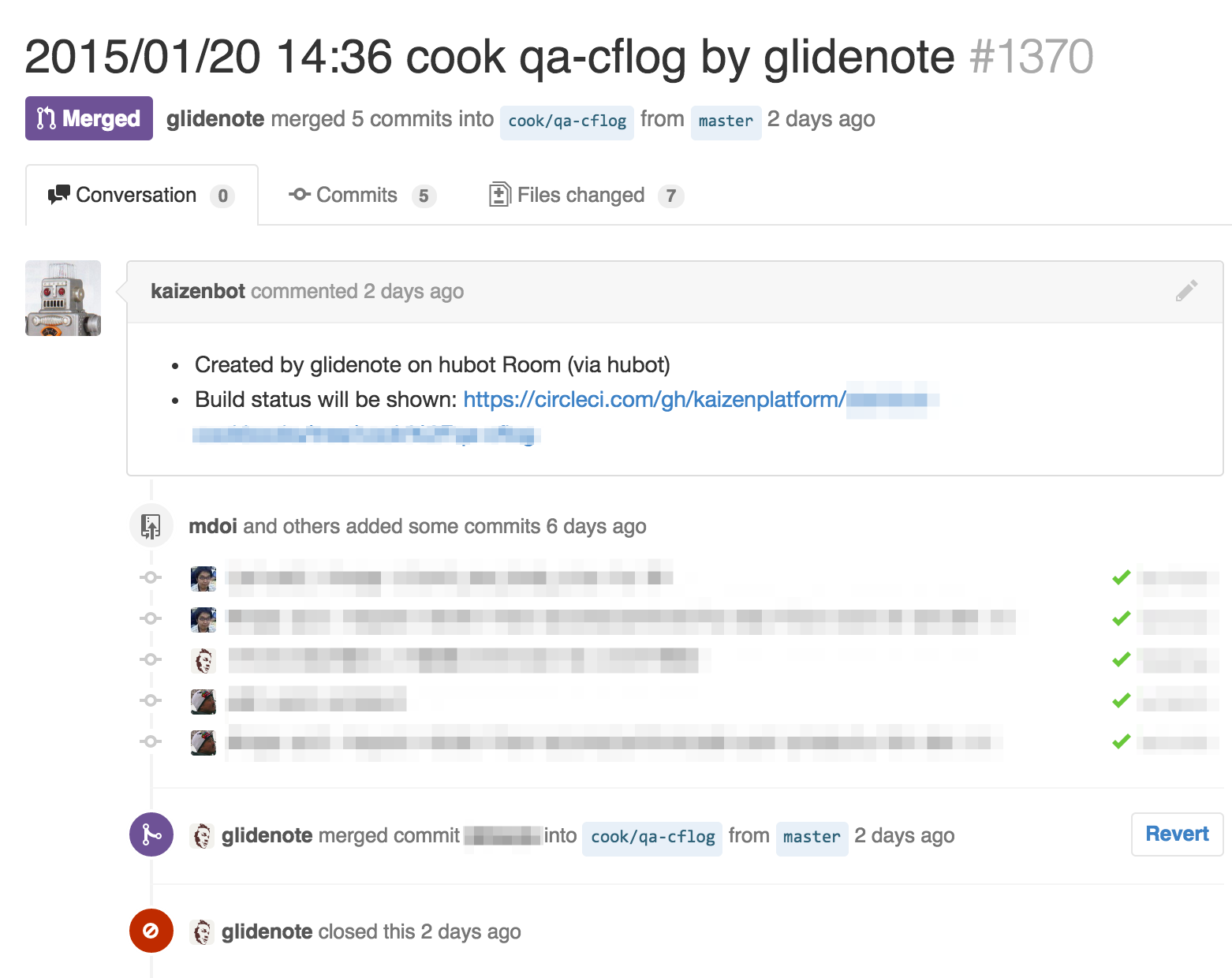
mergeを契機にCircleCI経由でサーバにChefを適用
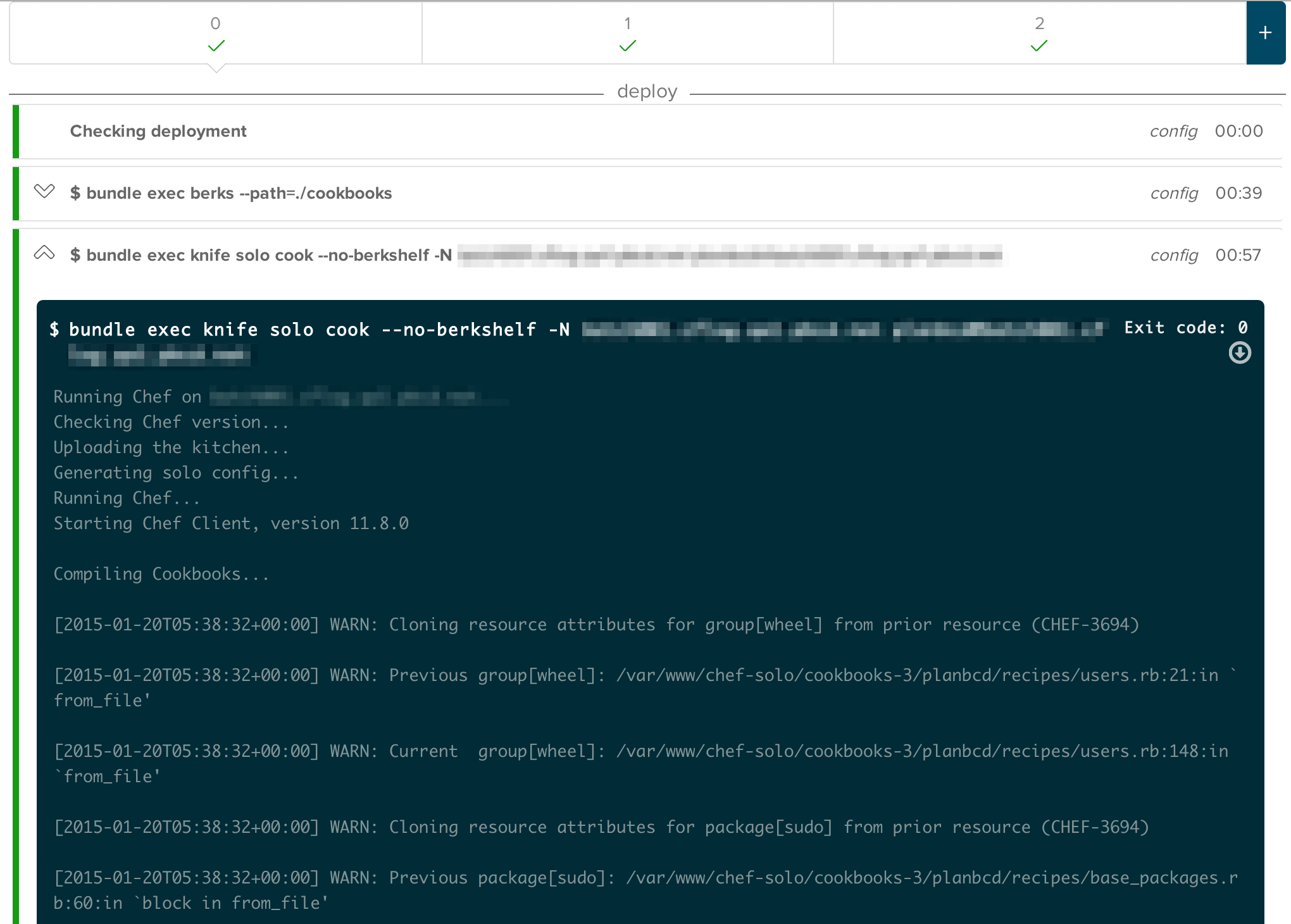
というようになっていて、手元やサーバからコマンドラインを操作して実行することはない。
これが可能なのもServerspecにより、インフラコードのテストが行われているためであり、Serverspecの功績は非常に大きい。
Serverspec本を読むことは、Serverspecという強力な武器を手にして、飛躍的に進化し続けているWeb系インフラエンジニアを知るために 最も有用な手段である。
最近1週間くらいずっとAmazonでベストセラー1位になっているので、もう既にみんな読んでいると思いますが傑作です。

本書内で拙作の
- glidenote/serverspec-snippets
- vim-quickrunでServerspecをカーソル行単位でテストして編集効率を10倍にする - Glide Note - グライドノート
を紹介して頂いて、期せずしてオライリー本デビューをさせていただきました。ありがとうございます